The IMPROVED Dataset
Dataset Focus
The XLPSR challenge evaluates text reconstruction accuracy rather than pixel-level fidelity. No high-resolution clean frames are provided—models must recover license plate text directly from degraded low-resolution inputs.
The challenge is built upon the proprietary IMPROVED dataset (In-the-wild with Multi-Perspective Realistic Observations for Vehicle Evidence and license-plate recognition), specifically curated to capture the diversity and complexity of real operational environments.
Dataset Characteristics
- Short real-world video clips (up to 10 frames) of moving vehicles with French license plates
- Multiple acquisition devices (consumer cameras, surveillance cameras, smartphones)
- Wide range of distances (10–100 meters)
- Variable lighting conditions
- Different weather conditions (clear, cloudy)
- Large viewpoint variability (frontal, oblique, steep angle)
- Strong natural degradations (motion blur, sensor noise, compression artifacts)
Data Format
Each video clip is paired with:
- Low-resolution input frames extracted from the video
- Ground-truth license plate text (character string) avalaible only for the developement set.
- Frame-level metadata (Video clip ID and license plate bounding boxes)
Note: High-resolution reference images are not provided to emphasize the real-world super-resolution task.
Acquisition Site
Acquisition Circuit
The dataset was acquired at the Saint-Laurent-de-Mûre circuit in France. The highlighted portion of the circuit below was used for capturing the video sequences with vehicles in motion under realistic conditions.
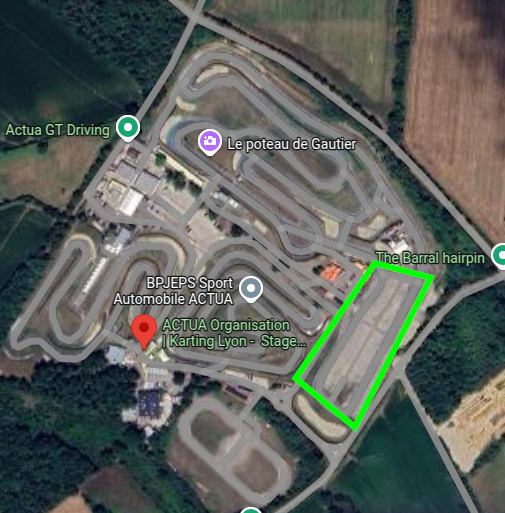
Figure 1: Saint-Laurent-de-Mûre circuit with highlighted acquisition zone.
Camera Configuration
The dataset features 17 different cameras covering a wide spectrum of imaging devices:
- Surveillance cameras: Reolink, Instar, Hikvision, Dahua
- Smartphones: Huawei P40 Pro, iPhone 15/15 Plus, Xiaomi Redmi Note 13, Huawei Honor 9X
- Professional cameras: Blackmagic micro studio 4K (x2), Panasonic Lumix DMC-G70
- Specialized: Hikvision fisheye camera (severe distortion), infrared camera
License Plate Examples
French License Plate Format
The dataset exclusively contains old and new French license plates. The format for old license plates 123-AAA-12 or 1234-AA-12 (3 or 4 degits, 2 or 3 letters, 2 degits). And the format for new license late is: AA-123-AA (2 letters, 3 digits, 2 letters).

Figure 2: Examples of French license plates from the acquisition.
File Format & Structure
Detection Annotations Format
Each sequence folder (10 frames) contains a detections.json file with the following structure:
[
{
"frame": "000000.png",
"license_plate_coordinates": [x1, y1, x2, y2]
},
{
"frame": "000001.png",
"license_plate_coordinates": [x1, y1, x2, y2]
},
...
]
Coordinates are in [top-left x, top-left y, bottom-right x, bottom-right y] format.
Directory Structure
dataset/ ├── development/ │ └── seq_001/ │ ├── 000000.png │ ├── ... │ ├── 000009.png │ └── detections.json ├── public_validation/ │ └── seq_002/ │ ├── 000000.png │ ├── ... │ └── detections.json └── ground_truth.csv (global ground truth file)
Each sequence contains exactly 10 consecutive frames.
Expected prediction file format
Participant should provide a zip file containing prediction.csv, it should include the sequence IDs and the coresponding predicted license plate text, as bellow:
sequence_id,license_plate seq_001,AB123CD seq_002,EF456GH seq_002,457DEX16 ...
Dataset Splits
The IMPROVED dataset is divided into three distinct sets to ensure fair evaluation and rigorous benchmarking:
Development Set
For Local Benchmarking & Validation
39 sequences (390 images)
- Complete low-resolution video frames
- Full ground-truth license plate labels
- Detection coordinates in JSON format
Purpose: Allows participants to develop, test, and validate their models locally before submission.
Public Validation Set
For Public Leaderboard
347 sequences (3,470 images)
- Low-resolution frames only (no ground truth)
- Detection coordinates in JSON format
Purpose: Enables participants to benchmark against others and track progress on the public leaderboard.
Blind Test Set
For Final Evaluation
88 unreleazed sequences (880 images)
- 16 completely unseen license plates
- Similar diversity to development set
- Evaluated on organizers' servers
Purpose: Ensures fair, unbiased final evaluation of all submissions on previously unseen data.
Training Policy & Guidelines
Training Guidelines
- External data permitted: Participants may use any external data (synthetic, public, or proprietary) for training their models.
- Model constraints: No restrictions on model architecture, size, or training methodology.
- Pre-trained models: Use of publicly available pre-trained models is allowed and encouraged.
- Data augmentation: Participants may augment the provided data with synthetic degradations.
- Submission requirements: Final models must be submitted as Docker containers for reproducibility (top teams and on invitation only).
Important Notes
- The blind test set will not be released to participants at any time
- Public leaderboard rankings are indicative only
- Final ranking is based exclusively on blind test set performance and expert evaluation
- All submissions must follow the
sequence_id,predicted_lpCSV format - Dataset license agreement must be signed during registration
Dataset Release Schedule
Development Set: ~February 20, 2026 - Immediately upon registration approval
Public Validation Set: March 1, 2026 - Leaderboard opens
Blind Test Set: Never released - remains exclusively with organizers